Safety Alignment Can Be Not Superficial
With Explicit Safety Signals
Jianwei Li1, Jung-Eun Kim1
1North Carolina State University
A lightweight and robust safety alignment method for LLMs using explicit safety classification signals and strategic decoding.
Accepted at ICML 2025
Abstract
Recent studies on the safety alignment of large language models (LLMs) have revealed that existing approaches often operate superficially, leaving models vulnerable to various adversarial attacks. Despite their significance, these studies generally fail to offer actionable solutions beyond data augmentation for achieving more robust safety mechanisms. This paper identifies a fundamental cause of this superficiality: existing alignment approaches often presume that models can implicitly learn a safety-related reasoning task during the alignment process, enabling them to refuse harmful requests. However, the learned safety signals are often diluted by other competing objectives, leading models to struggle with drawing a firm safety-conscious decision boundary when confronted with adversarial attacks. Based on this observation, by explicitly introducing a safety-related binary classification task and integrating its signals with our attention and decoding strategies, we eliminate this ambiguity and allow models to respond more responsibly to malicious queries. We emphasize that, with less than 0.2x overhead cost, our approach enables LLMs to assess the safety of both the query and the previously generated tokens at each necessary generating step. Extensive experiments demonstrate that our method significantly improves the resilience of LLMs against various adversarial attacks, offering a promising pathway toward more robust generative AI systems.
Motivation & Background
Motivation
Although existing alignment methods like SFT, DPO, and RLHF are widely used to ensure the safety of large language models (LLMs), recent research reveals that these approaches are often superficial. Aligned models may appear safe initially but still respond to adversarial prompts, subtle fine-tuning adjustments, or decoding manipulation with harmful content. These methods often fail to maintain safety across the entire generation process, especially in complex scenarios where harmful content appears in the middle or end of a response.
Background
Prior studies have suggested that safety alignment can be interpreted as an implicit binary classification task. However, safety-related signals are frequently diluted by other objectives like human preferences for style and tone, leading to model confusion under adversarial pressure. Inspired by BERT, our work introduces an explicit safety classification task using a [CLS] token, combined with strategic attention and decoding strategies. This design enables more robust safety alignment by reinforcing clear decision boundaries and re-evaluating safety dynamically throughout generation, ensuring better defense against a wide range of adversarial attacks.
Methodology
1. Binary Classification Task - Explicit Safety Signals
Inspired by BERT, we introduce a dedicated [CLS] token to each input, enabling the model to classify whether the input and its current generation trajectory are benign or malicious. This classification task runs alongside the language modeling objective but is isolated via a tailored attention mechanism and controlled loss weighting. These design choices ensure the model maintains generative performance while extracting explicit safety signals.
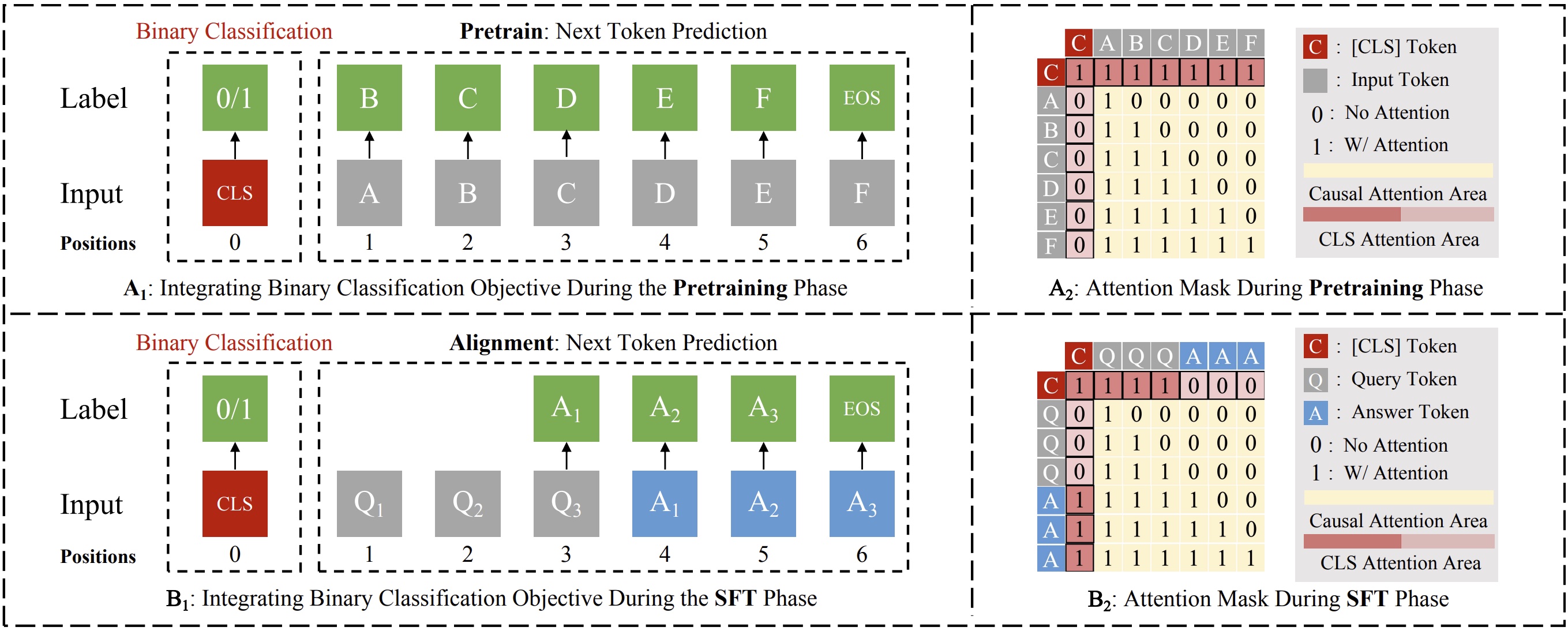
2. Strategic Attention Design - Implicit Leverage
We allow the [CLS] token to dynamically re-attend to query and response tokens during generation. This enables the model to continuously assess safety without breaking causal attention. Our design includes three adaptive rules depending on whether the input is benign, malicious, or transitions mid-generation. These rules allow nuanced safety tracking across complex prompt structures.

3. Strategic Decoding Strategy - Explicit Leverage
To strengthen controllability, we explicitly use the [CLS] prediction to modify the decoding process. When malicious intent is detected (either initially or during generation), our strategy inserts a refusal prefix with a chain-of-thought justification. This balances false positive risk with interpretability and ensures prompt safety-aware shifts in response generation.

Experiment Results
We evaluate our approach using Llama2-7B as the base model and Mistral-7B-Instruct-v0.2 as the aligned model. Baselines include: (1) models fine-tuned with SFT and SFT+DPO, (2) official RLHF-aligned releases, (3) state-of-the-art models using augmented datasets, and (4) a cross-family comparison with Llama2-7B-Chat. Our method significantly outperforms all baselines in safety performance: (1) reduces ASR from 93% to under 1% in several jailbreak settings, (2) competes with or surpasses models fine-tuned with DPO or RLHF, (3) beats state-of-the-art augmented models, and (4) upgrades Mistral-7B-Instruct to exceed Llama2-7B-Chat in safety.


These results align with the Superficial Safety Alignment Hypothesis and confirm that explicit safety signals substantially improve model robustness.