Safety Alignment Can Be Not Superficial
With Explicit Safety Signals
A lightweight and robust safety alignment method for LLMs using an explicit safety classification signal and strategic attention & decoding.
Jianwei Li1·Jung-Eun Kim1
1Department of Computer Science, North Carolina State University
01 · Overview
Abstract
Recent studies on the safety alignment of large language models (LLMs) have revealed that existing approaches often operate superficially, leaving models vulnerable to various adversarial attacks. Despite their significance, these studies generally fail to offer actionable solutions beyond data augmentation for achieving more robust safety mechanisms.
This paper identifies a fundamental cause of this superficiality: existing alignment approaches often presume that models can implicitly learn a safety-related reasoning task during the alignment process. However, the learned safety signals are often diluted by other competing objectives, leading models to struggle with drawing a firm safety-conscious decision boundary under adversarial pressure.
By explicitly introducing a safety-related binary classification task and integrating its signals with our attention and decoding strategies, we eliminate this ambiguity and allow models to respond more responsibly to malicious queries.
Explicit Safety Signal
We add a dedicated [CLS] token that explicitly classifies whether the input and current trajectory are benign or malicious.
Strategic Attention & Decoding
The CLS prediction re-attends to query/response tokens and steers decoding — safety is re-evaluated per step, not only at the start.
Robust with Low Overhead
With less than 0.2x overhead cost, our method drops attack success rates from 93% → <1% on multiple jailbreak settings.
02 · Why It Matters
Motivation & Background
Motivation
Although alignment methods like SFT, DPO, and RLHF are widely used to ensure LLM safety, recent research reveals these approaches are often superficial. Aligned models may look safe initially but still produce harmful content under adversarial prompts, subtle fine-tuning, or decoding manipulation — especially when the harmful content appears in the middle or end of a response, where current methods fail to maintain safety across the full generation process.
Background
Prior work suggests safety alignment can be interpreted as an implicit binary classification task. But safety-related signals get diluted by competing objectives (style, tone, human preferences), confusing the model under adversarial pressure. Inspired by BERT, we introduce an explicit safety classification task using a [CLS] token, combined with strategic attention and decoding — reinforcing clear decision boundaries and re-evaluating safety dynamically throughout generation.
[CLS], re-evaluated at each generation step.03 · Approach
Methodology
Three components, working together to make safety alignment not superficial.
Binary Classification Task — Explicit Safety Signals
Inspired by BERT, we add a dedicated [CLS] token to each input so the model can classify whether the input and its current generation trajectory are benign or malicious. The classification task runs alongside the language modeling objective but is isolated via a tailored attention mechanism and controlled loss weighting — generative performance is preserved while explicit safety signals are extracted.
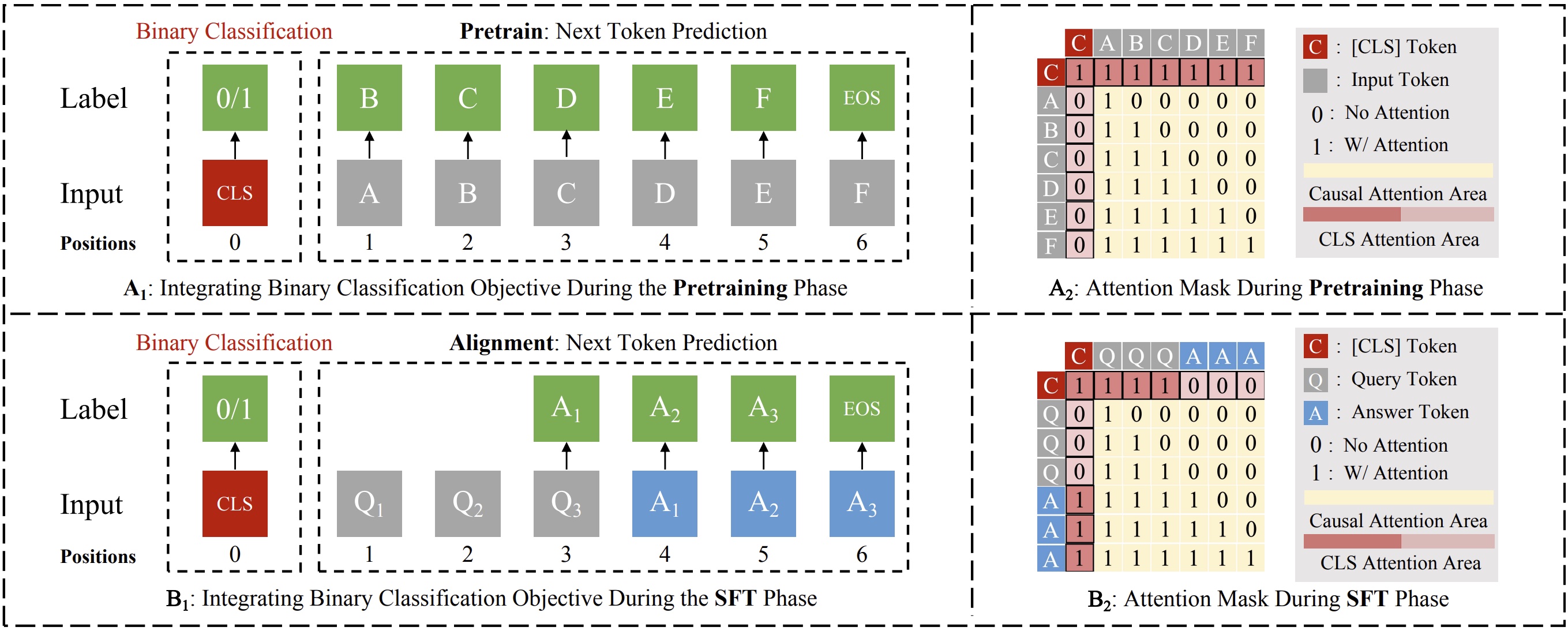
Strategic Attention Design — Implicit Leverage
We let the [CLS] token dynamically re-attend to query and response tokens during generation, continuously assessing safety without breaking causal attention. Three adaptive rules handle benign, malicious, or mid-generation transition cases — enabling nuanced safety tracking across complex prompt structures.

Strategic Decoding Strategy — Explicit Leverage
To strengthen controllability, we explicitly use the [CLS] prediction to modify decoding. When malicious intent is detected (either initially or mid-generation), our strategy inserts a refusal prefix with chain-of-thought justification — balancing false-positive risk with interpretability while ensuring prompt safety-aware shifts in response generation.

04 · Results
Experiment Results
We evaluate our approach using Llama2-7B as the base model and Mistral-7B-Instruct-v0.2 as the aligned model.
- SFT and SFT + DPO fine-tuned models
- Official RLHF-aligned releases
- State-of-the-art models with augmented data
- Cross-family comparison with Llama2-7B-Chat
- Reduces ASR from 93% → <1% in several jailbreak settings
- Competes with or surpasses models fine-tuned via DPO / RLHF
- Beats state-of-the-art augmented-data models
- Upgrades Mistral-7B-Instruct to exceed Llama2-7B-Chat in safety


These results align with the Superficial Safety Alignment Hypothesis and confirm that explicit safety signals substantially improve model robustness.
05 · Cite Us
BibTeX
If you find our work helpful, please consider citing us.
@inproceedings{li2025saess,
title = {Safety Alignment Can Be Not Superficial With Explicit Safety Signals},
author = {Jianwei Li and Jung-Eun Kim},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2025},
url = {https://arxiv.org/abs/2505.17072}
}